
In this post, we are going to explore one of the most useful functions in Google Data Studio, the CASE. I personally think that knowing how to write a CASE is not only helpful in Data Studio, but also it allows you to understand how computer logic works. In addition, I have added a section on how to compose the new Simplified CASE statements.
*NEW – By popular demand, I have decided to expand the comprehensive guide on CASE and added IF statements, as the Google Data Studio team has had some incredible updates over the past year. Enjoy!
What is the Data Studio CASE function?
The CASE function returns dimensions and metrics based on conditional expressions; it is often used to create new groupings of data and sort them in categories. Let’s imagine the following scenario. In the table below, you have a paid digital marketing campaign that includes “EN” and “FR” in the campaign name. However, you want to see the table below only per “Language”. This is where you can use the CASE function to write a specific statement.
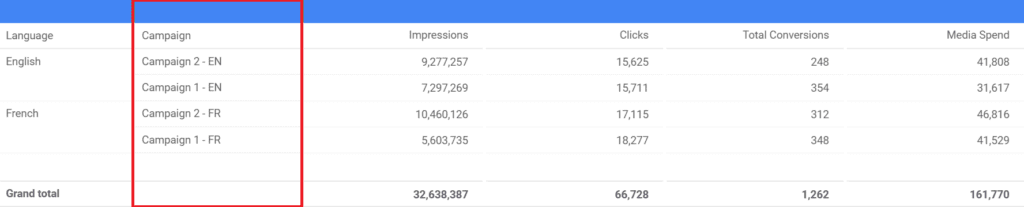
The trick with the CASE function is that you often have to find a unique common denominator to parse the data correctly. In the statement below, I am opening the CASE with a WHEN, specifying the first condition. Then adding IN, which instructs Data Studio that I will be listing text strings. Finally, I go ahead and choose my campaign name(s) and specify with THEN what I want to name the result of my WHEN condition. I know…. this is a bit of a tongue twister.

The result is exactly what we were looking for. Now if we want to see the campaign simply filtered by the “Language” dimension, we can even exclude “Campaign”.
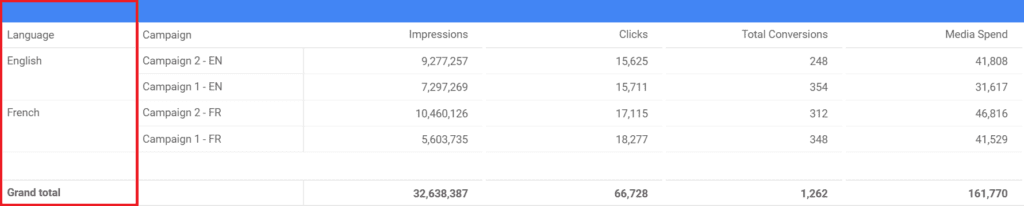
How to use REGEXP_MATCH function within CASE?
Now, what happens if things get more complicated. For example, in the “Complex Campaign” dimension, we have a lot of different and unique campaign iterations. If we were to use IN, then the list in the CASE function is going to grow substantially and we are more likely to make a mistake while writing it. This is why we are going to try out the REGEXP_MATCH function, also referred to as regex.
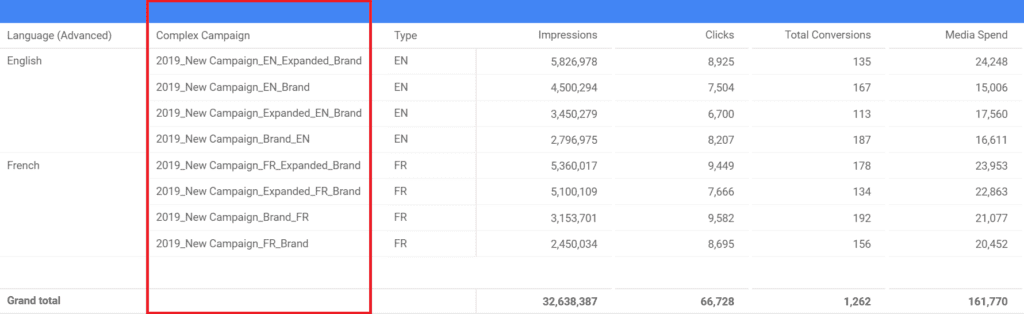
Quick background: Regular expressions are a notation for describing sets of character in a specific word or any text string. Google Data Studio (and most Google products) uses the RE2-style syntax.
We start the WHEN statement the same way, without much difference. However, the modified dimension i.e. “Campaign” is inside brackets, unlike IN where it is outside. All we are doing with the regular expression is telling Data Studio that every time the capital letters “EN” or “FR” are spotted in the “Complex Campaign” dimension, the text strings should be named “English” and “French”, respectively. In a little bit more detail:

How to write simplified CASE statements by declaring a field to test once?
In recent feature updates, Google has made it even easier to write repetitive CASE statements by declaring the field at the beginning. For example, if you have the same “Campaign” name, but this time, you want to use the year as a matching criteria.
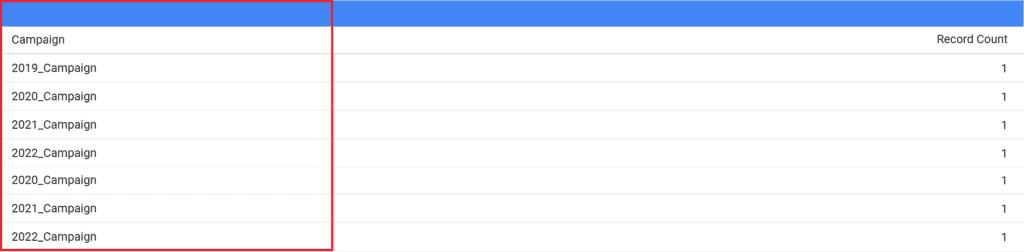
Following the same logic as our past examples, you would normally write this standard CASE statement.

However, with the simplified CASE statement, you can do the following and save a bit of time!

How to create IF statements in Google Data Studio?
This has been a highly anticipated function and everyone was ecstatic when Google brought it to life. Similar to other platforms, you can use the IF function to return a dimension based on a given condition or rule. The basic syntax is as follow:
IF(condition, true_result, false_result)
Parameters
- Condition. This is the expression to evaluate. It consists of any valid boolean expression.
- True_result: This refers to the value that will be returned if the condition is true. It can be any valid expression.
- False_result: This refers to the value that will be returned if the condition is false. It can be any valid expression
Let’s look at an example. This simple condition will calculate if “Actual Sales” exceed the “Forecast Sales”. If they do, your new column will the “Bonus” by 1.4, which presumably is going to info you sales team. Then, bonuses will be distributed accordingly.
IF(Actual Sales > Forecast Sales, Bonus * 1.4, Bonus)In addition, you can use a more complex condition with regular expression matching and logical AND. Although AND and OR allow you to test multiple conditions, simple CASE and CASE are the best to use if there are more than two possible results. Let’s see how that works.
IF (Event name = "purchase" AND (REGEXP_MATCH(Page path, ".*clothes.*") OR REGEXP_MATCH(Page path, ".*hoodies.*")), "hoodies Sales", Page title)As you can see, the IF statement can be quite powerful.
Data Studio CASE examples from the Media Agency world:
These are few of the most common CASE statements across the Google Marketing Platform (GMP), ready to be copy/pasted!
Google Campaign Manager (CM) – Language
CASE
WHEN REGEXP_MATCH(Campaign, '.*(EN).*') THEN 'English'
WHEN REGEXP_MATCH(Campaign, '.*(FR).*') THEN 'French'
ELSE 'Other Language'
ENDDisplay and Video 360 (DV360) – Language
CASE
WHEN REGEXP_MATCH(Insertion Order, '.*(EN).*') THEN 'English'
WHEN REGEXP_MATCH(Insertion Order, '.*(FR).*') THEN 'French'
ELSE 'Other Language'
ENDDisplay and Video 360 (DV360) – Standard Media Tactics
CASE
WHEN REGEXP_MATCH(Line Item, '.*(Remarketing).*') THEN 'Remarketing'
WHEN REGEXP_MATCH(Line Item, '.*(Lookalikes).*') THEN 'Lookalikes'
WHEN REGEXP_MATCH(Line Item, '.*(Prospecting).*') THEN 'Prospecting'
ELSE 'Other Tactic'
ENDGoogle Ads – Device Type
CASE
WHEN REGEXP_MATCH(Campaign, '.*((M|m)obile).*') THEN 'Mobile'
WHEN REGEXP_MATCH(Campaign, '.*((T|t)ablet).*') THEN 'Tablet'
WHEN REGEXP_MATCH(Campaign, '.*((C|c)omputer).*') THEN 'Desktop'
ELSE 'Other'
ENDGoogle Ads – Age Breakdown (this cleans up your default age dimension)
CASE
WHEN Age IN ('Undetermined') THEN 'Unknown'
WHEN Age IN ('18to24') THEN 'A18-24'
WHEN Age IN ('25to34') THEN 'A25-34'
WHEN Age IN ('35to44') THEN 'A35-44'
WHEN Age IN ('45to54') THEN 'A45-54'
WHEN Age IN ('55to64') THEN 'A55-64'
WHEN Age IN ('gt64') THEN 'A65+'
ELSE 'N/A'
ENDGA360 or Google Analytics (Free) – Blog “Page” Sorting
CASE
WHEN REGEXP_MATCH(Page, ‘((?i).*.*/about.*).*’) THEN ‘About Us
WHEN REGEXP_MATCH(Page, ‘((?i).*.*/blog/.*).*’) THEN ‘Blog Posts’’
WHEN REGEXP_MATCH(Page, ‘((?i).*.*/contact$).*’) THEN ‘Contact Us’
WHEN REGEXP_MATCH(Page, ‘((?i).*^/blog$).*’) THEN ‘Blog Page’
WHEN REGEXP_MATCH(Page, ‘((?i).*^/solutions/.*).*’) THEN ‘Solutions Pages’
WHEN REGEXP_MATCH(Page, ‘((?i).*^/services$).*’) THEN ‘Services’
WHEN REGEXP_MATCH(Page, ‘((?i).*.*/blog/category/.*).*’) THEN ‘Blog Category Page’
WHEN REGEXP_MATCH(Page, ‘((?i).*^/products/.*).*’) THEN ‘Product Pages’
WHEN REGEXP_MATCH(Page, ‘((?i).*^/contact/.*).*’) THEN ‘Thank You – Contact’
CASE WHEN REGEXP_MATCH(Page, ‘((?i).*^/$|^/\\?.*).*’) THEN ‘Homepage’
ELSE ‘_Other’
END
I hope this was helpful! If you have any questions, feel free to DM me on LinkedIn or subscribe to my newsletter for more updates 🙂
Dynamic Dashboards and Data Analysis with Google Data Studio
If you want to learn how to build powerful data visualizations and unlock insights that can help you drive business results for your clients or employers, take a look at my full course on Udemy.

23 comments
Hey there,
Super useful article!
I’m using this to segment items within a table: CASE
WHEN REGEXP_MATCH(Campaign, ‘.*(Brand).*’) THEN ‘Brand’
WHEN REGEXP_MATCH(Campaign, ‘.*(Generic).*’) THEN ‘Generic’
WHEN REGEXP_MATCH(Campaign, ‘.*(Competitor).*’) THEN ‘Competitor’
ELSE ‘Other’
END
However, I can only see this segmentation when I keep a Dimension for “Campaign” active. As soon as I remove Campaign, the whole thing becomes broken.
You mentioned above “Now if we want to see the campaign simply filtered by the “Language” dimension, we can even exclude “Campaign”.” … how can I exclude?
Thank you!!!
Hey Valentina,
Thanks for reaching out and sorry for the delay. You should be able to remove the source dimension and replace it with the newly created CASE one. Normally, you just have to remove it from the dimensions menu on the side. Also, did you create the CASE at a report-level or data source-level (Resources -> Manage added data sources -> …)?
Regards,
Lachezar
Hey there
How do I use the case function when trying to get data between two dates.
for example. When the country is Kenya and the dates are between 1st March and 30th April give me 26 and when the country is Kenya and the dates are between 1 May and 30th June give me 70.
Hey Reginah,
Thanks for reaching out! Here is what you can do to activate your logic within a CASE statement. I have used the “[Sample] Google Analytics Data” in Data Studio to re-create the example:
CASE
WHEN Country ISO Code = “US” AND Date >= “20200301” AND Date <= "20200430" THEN "26" WHEN Country ISO Code = "US" AND Date >= “20200101” AND Date <= "20200229" THEN "70" ELSE "Other" END
I have put together a dashboard too.
Let me know if this works for you 🙂
Thanks,
Lachezar
Hey Lachezar,
I have tried using this example but I keep getting this error “Failed to create field. Please try again later.”. I am using a Heroku database for my report.
Regards,
Reginah
Hey Reginah,
This is interesting. I would recommend you to take a look at how your “Date” is formatted, as that might be the reason why you are getting the error. If possible, my recommendation would be to do the transformations in Heroku and then push the final table in Data Studio to avoid the additional rendering and limitations.
Thanks,
Lacho
Hi Lachezar,
This does not work.
Hey Pooya,
Are you referring to the same issue Reginah is experiencing or another section in the article?
Thanks,
Lacho
Hi Lachezar,
Can Data studio allow a table containing columns of text data type to filter a pivot table based on the number of unique or non-unique rows in 1 field. For example.
Region Country Campaign Status
Europe. England. ABC. Delayed
Europe. France ABC. Delayed
Europe. Germany ABC. Delayed
In Data studio, we want to show only 1 row if the status is the same of all countries and collapse the country row. Essentially its a form of de-duplication when the status is the same.
Hey Marshal, apologies for the delay in my reply. This is a great question! You can achieve the breakdown that you described by using the “Exapnd-Collapse” in a pivot table. I have sent you an e-mail with a sample Data Studio dashboard. Let me know if that is what you were looking for.
Hi Yes it was! Thank you for your help! We went using the option and it worked.
Great to hear it worked out Marshal! 🙂
Per your answer to Reginah Kanyi Date format. Does the regex syntax ever change? I have previously written CASE statements that worked when I wrote it, but now am unable to edit them. When I click on the calculated field to edit, it shows a red X, where when I saved it it was ok showing a green checkmark.
CASE
WHEN ( Date >= ‘20170401’ AND Date = ‘20180401’ AND Date = ‘20190401’ AND Date <= '20200331') THEN '2019 to 2020'
END
The code pasted incorrectly, the CASE is wrong.
Is there any way to write a case statement to say “if data in column A matches data in column B”? The use case is that I have rows where a purchase date is in column A. In column B I have the very first date that person ever purchased something. Column C is a unique identifier for that person. So if person A make five purchases over five months, I don’t have a way of only counting person A as a new purchaser in the first month that they purchased something. My thought is to say “WHEN column A matches column B THEN ‘Fist Purchase;” In theory, it would only append “First Purchase” on the rows where the purchase date and the first purchase date match, thereby allowing me to count the new purchasers month over month. I just can’t figure out a way to accomplish this. Any help would be greatly appreciated!
Hmm… this is an interesting case Keith and thanks for the comprehensive description 🙂 How about using the DATE_DIFF (for compatibility mode) or DATETIME_DIFF, which will allow you to get the difference between dates in the form of an integer. In that way, then the number is 0, then that will be a match and a first purchase. From there, you can write your CASE in a much easier way ^LA
Uff Guys, you are good. Thanks a lot.
Here is the case where I’m broke my head.
– We have a Guarantee by Countries (DE, US) [Created Field as CRG]
– Each Country has a different Guarantee. [DE=25, US=44]
– This Guarantee could be in dynamic Changes by dates, days converted to numbers.
– Guarantee could be excluded on Weekends from 20210322 for one country, so create the field for each country is not so good.
And here I’m stuck.
CASE
WHEN (country IN (“Denmark”, “Sweden”) AND CRG IN (“Yes”)) THEN lead*25
WHEN (country IN (“Italy”) AND CRG IN (“Yes”) AND dateWeekends IN (“No”)) THEN lead*20
WHEN (country IN (“Greece”) AND (dateNumber !=20210626) AND (dateNumber !=20210627)) THEN leads*15
ELSE 0
END
The question is.
What is the best way to exclude Weekends after 20210322 and save all data before this date?
Hey McDealinger, thanks for sharing 🙂 I went ahead and posted your question in one of our Data Studio Q&A groups to ask the larger community and here is one suggested solution by user “Anisa Boumrifak”:
—–
Hmm – I doubt this can be done with just one CASE WHEN, even if the syntax was conforming to DS’s expectations. Here comes my take on this, just thoughts though – I have not tried it myself:
1) I would probably use one field F1 for an IF-clausesto handle the time spans and then have 2 CASE WHENs nested in there to get the rules per country and time frame right but without adding the formula, just numbers (25 instead of lead*25).
2) Then maybe F1 need to be used in a second field F2 in an operation such as SUM() so it can be used as a metric () with other metrics – but if we are lucky we don’t have to that extra step
3) Now this field can be either used for a calculation with leads directly or it can be used by blending filtered tables
One would probably have to play around a bit to see if filtering weekends from tables and then blending those tables works better than excluding them in the CASE WHEN…
As stated before: this is just an approach from the top of my head
—–
Hope this helps! ^LA
Hey Great resource and thanks for sharing Lachezar! Have you noticed some ratio metrics crashing when using this grouping method? For example, when I segment campaigns by name on a Google Ads connector, I can aggregate impressions, clicks, and cost, but the table breaks when I add CTR, Conv. Rate, or Avg. cost per click. Any ideas why this might be happening?
Hi,
I am really perplexed by what I thought would be a simple task in Data Studio. I am producing a monthly report of total searches (using the table’s Record Count) for 4 of our websites. No problem. I would like to compare each month’s searches with the previous month and I have been unable to figure out how to do that calculation. I have gotten as far as creating the “1 month prior” date field using this formula: Date(Datetime_sub(PDate, interval 1 Month))
How can I total the searches (using the Record Count field) for this time period?
Hi
I have I I have tried using below expression for B+G however doesn’t seem to work
WHEN REGEXP_MATCH(Campaign, ‘.*(B+G).*’) THEN ‘B+G’
However same expression works on using BplusG
Does it have to do with character selection
Hey Vanik, the “+” is considered a special regular expression character, which has a specific function. If you still want to use it, then you will have to use the “\” character following the “+” to tell the RegEx not to use it as character with special meaning (in other words “B+\G”). Here is more info on regular expressions that describes those characters.
I’m running 2 separate campaigns ‘Brand V1’ and ‘Generic V1’.
I want to see the performance for V1 campaign (combined)
I am using this:
CASE
WHEN REGEXP_MATCH(Campaign, “.*V1.*”) THEN “V1”
END
I am able to see the correct metrics (Impressions, Clicks, Cost). However, CTR, Impression share, Impression share Lost Budget is also being added together rather than displaying the actual aggregate.
How to resolve this?
Comments are closed.